Capítulo 1 Riqueza total y de muestreo
La riqueza es definida como el número de especies que habitan en una comunidad espacial y temporalmente homogénea. Posiblemente es la forma más directa y clara de medir la diversidad biológica (Sarkar, 2002; Magurran, 2004). Sin embargo, medir la riqueza de forma precisa no es una tarea sencilla (Magurran, 2004). Como ecólogos estamos interesados encontrar patrones en la riqueza total entre comunidades, a partir de una muestra de esa comunidad. De tal forma necesitamos asegurar que nuestra muestra es representativa de la comunidad.
Cuando muestreamos una comunidad el número de especies observadas aumenta con el esfuerzo de muestreo, aunque la riqueza de la comunidad no cambie. Por ello, una comparación de la riqueza es posible sólo a partir de inventarios completos, lo que generalmente es poco práctico o muy difícil de lograr (González-Oreja et al. 2010).
Pero ¿qué es un inventario completo? ¿Cómo puedo saber si mi inventario ha sido lo suficientemente bueno como para registrar todas las especies?. Una manera de evaluar si el esfuerzo de muestreo ha sido exitoso es dibujar una curva de acumulación de especies. Esperamos que la curva incremente rápidamente con bajo número de muestras, pero que esta acumulación vaya estabilizándose a medida que el muestreo aumenta y logra capturar toda la riqueza de un determinado sitio. Existen algunos modelos que son usados para generar las curvas de acumulación de especies. El modelo básico de acumulación de especies propone la acumulación de especies cuando el número de sitios aumenta en el orden en que fueron muestreados. Otros métodos alternativos proponen la acumulación repetida en orden aleatorio (Oksanen, 2015).
A continuación veremos cómo implementar estos modelos en R. Usaremos los datos de vegetación de la Isla de Barro Colorado (BCI por sus siglas en ingles) para ajustar las curvas de acumulación de especies. Las funciones que usaremos se encuentran en el paquete vegan.
library(vegan) #Cargamos el paquete
data(BCI) #cargamos los datos
set.seed(18) #definimos una muestra aleatoria similar
#Obtenemos una submuestra de BCI
BCI_sub <- BCI[c(sample(1:50, 10, replace = TRUE)),]
BCI_sub <- BCI_sub[,colSums(BCI_sub)>=1 ]
#Eliminamos las especies sin datosAhora realizamos la curva de acumulación de especies por parcelas. Utilizamos la función specaccum del paquete vegan, el argumento method permite generar una curva con orden impuesto por el colector.
col<-specaccum(BCI_sub, method = "collector")
plot(col, xlab="Parcelas", ylab="Número de especies", col="blue")
points(col$richness, pch=19, col="darkblue")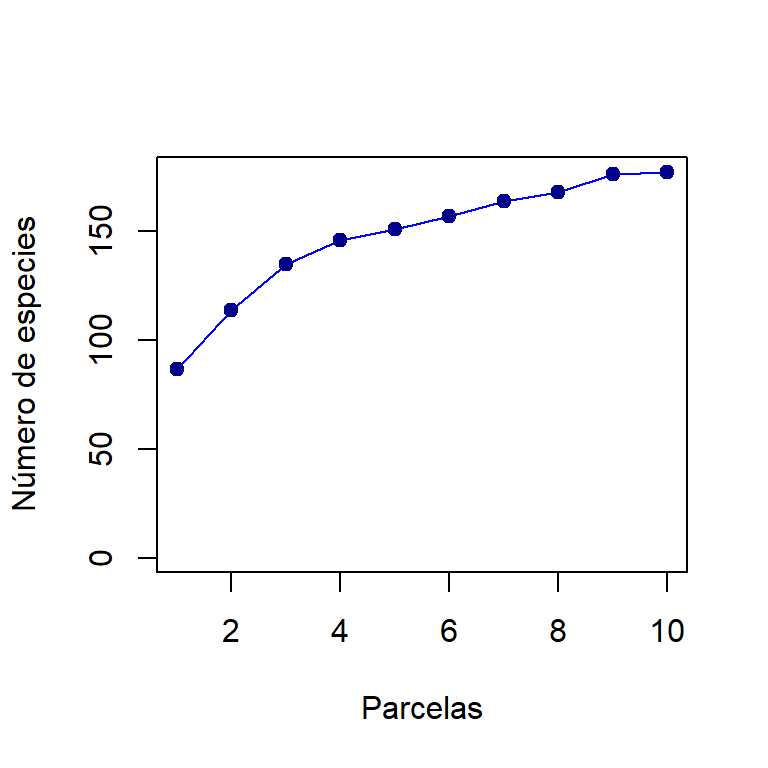
Figure 1.1: Curva de acumulación de especies
En la figura 1.1 podemos ver como la riqueza incrementa con el aumento del área muestreal, cada nueva muestra incluye nuevas especies a la comunidad. Podemos observar que la curva muestra “saltos”, alguna parcela incluye más especies nuevas que otras. La forma de esta curva está dada por el orden en el cual las parcelas fueron subidas por el colector. Aunque la curva de acumulación de especies nos permite evaluar como nuestro muestreo incorpora especies y si hemos tenido un buen muestreo, esta es muy dependiente del orden en el cual se dispongan las muestras. Una forma más eficiente sería aleatorizar el orden y construir una curva, este proceso es conocido como rarefacción.